Welcome to wuxy's Blog!
本站是wuxy的开发,阅读记录-
Hex文件解析研究(含源码)
课题背景
之所以对Hex文件格式其了研究的想法,是因为想造轮子了,想手动编码实现下载hex文件当MCU中,而不是通过官方/非官方的下载软件,如:keil,Jtag,flyMCU等,虽然,那些软件确实已经能够解决基本的需求,但是想要深入定制下载器,还是不够的。
比如,我想通过无线的形式传输Hex文件,而Hex文件却是二进制文件,很难直接通过无线模块传输,而必须转化为16进制字符。而在发送和接收时都需要解析和反解析。
比如,在手动编码实现SWD协议时,数据也是通过字符的形式发送到目标板上的。
本文介绍了2种Hex文件,ARM-MCU和Intel的,我亲测了ARM-MCU的,但是基本格式差不多。
HEX文件格式详解-MCU
参考链接:http://www.forwhat.cn/post-240.html,另外在CSDN上也能搜索到很多,本文整理了比较完善的。
Hex文件是可以烧录到MCU中,被MCU执行的一种文件格式。如果用记事本打开可发现,整个文件以行为单位,每行以冒号开头,内容全部为16进制码(以ASCII码形式显示)。Hex文件可以按照如下的方式进行拆分来分析其中的内容:
例如 “:1000080080318B1E0828092820280B1D0C280D2854”可以被看作“0x10 0x00 0x08 0x00 0x80 0x31 0x8B 0x1E 0x08 0x28 0x09 0x28 0x20 0x28 0x0B 0x1D 0x0C 0x28 0x0D 0x28 0x54”
第一个字节 0x10表示本行数据的长度;
第二、三字节 0x00 0x08表示本行数据的起始地址;
第四字节 0x00表示数据类型,数据类型有:0x00、0x01、0x02、0x03、0x04、0x05。
‘00’ Data Rrecord:用来记录数据,HEX文件的大部分记录都是数据记录
‘01’ End of File Record: 用来标识文件结束,放在文件的最后,标识HEX文件的结尾
‘02’ Extended Segment Address Record: 用来标识扩展段地址的记录
‘03’ Start Segment Address Record:开始段地址记录
‘04’ Extended Linear Address Record: 用来标识扩展线性地址的记录
‘05’ Start Linear Address Record:开始线性地址记录
然后是数据,最后一个字节 0x54为校验和。
校验和的算法为:计算0x54前所有16进制码的累加和(不计进位),检验和 = 0x100 - 累加和
在上面的后2种记录,都是用来提供地址信息的。每次碰到这2个记录的时候,都可以根据记录计算出一个“基”地址。对于后面的数据记录,计算地址的时候,都是以这些“基”地址为基础的。
HEX文件都是由记录(RECORD)组成的。在HEX文件里面,每一行代表一个记录。记录的基本格式为:
Record mark ‘:’
Length
Load offset
Record type
INFO or DATA
CHKSUM
1 byte
1 byte
2 bytes
1 byte
n bytes
1 byte
看个例子:
:020000040008F2
:10000400FF00A0E314209FE5001092E5011092E5A3
:00000001FF
对上面的HEX文件进行分析:
第1条记录的长度为02,LOAD OFFSET为0000,RECTYPE为04,说明该记录为扩展段地址记录。数据为0008,校验和为F2。从这个记录的长度和数据,我们可以计算出一个基地址,这个地址为(0x0008 « 16)。后面的数据记录都以这个地址为基地址。
第2条记录的长度为10(16),LOAD OFFSET为0004,RECTYPE为00,说明该记录为数据记录。数据为FF00A0E314209FE5001092E5011092E5,共16个BYTE。这个记录的校验和为A3。此时的基地址为0X80000,加上OFFSET,这个记录里的16BYTE的数据的起始地址就是0x80000 + 0x0004 = 0x80004.
第3条记录的长度为00,LOAD OFFSET为0000,TYPE = 01,校验和为FF。说明这个是一个END OF FILE RECORD,标识文件的结尾。
在上面这个例子里,实际的数据只有16个BYTE:FF00A0E314209FE5001092E5011092E5,其起始地址为0x0004.
其实文件格式很简单,而目标板真正需要的只有实际数据,根据上面的格式说明,我编写了一个小程序,用于直接由Hex文件生成C代码数组文件。本人亲测有效,如有问题可以邮件联系我。
#run by python3.6 in IDLE #author:wuxy #date:2019-01-04 #function:将hex文件中有效数据提取到C数组文件。 size=0 def parseHexPerLine(str): global size if len(str)<1: return if str[0]!=':': print('the first char is not :') return dataLen=int(str[1:3],16)*2 #数据长度,实际是字符串的长度 # print('dataLen: ',dataLen) if str[7:9]=='00': #类型为数据 size+=dataLen dataStr=str[9:9+dataLen] parseStr='' for i in range(0,dataLen,2): parseStr+='0x' parseStr+=dataStr[i:i+2] parseStr+=',' parseStr+='\n' #为了排版需要 return parseStr else: return '' fileName=input('please input hex file name: ') cArrayFile=open('aArrayFile.c','w') cArrayFile.write('const unsigned char ') cArrayFile.write(fileName) cArrayFile.write('[]={\n') for line in open(fileName): print(line) str=parseHexPerLine(line) print(str) cArrayFile.write(str) cArrayFile.seek(cArrayFile.tell()-3) #剔除最后一个逗号,本来应该是-1,但是由于前面加了一个'\n'. cArrayFile.write('};') cArrayFile.close() size/=2 print('size: ',size)其中,size是用于记录数组的大小。
写的比较简陋,但是很实用。
HEX文件格式解析-Intel
Intel HEX 文件是由一行行符合Intel HEX 文件格式的文本所 构 成的ASCII 文本文件。在Intel HEX 文件中,每一行包含一 个 HEX 记录 。 这 些 记录 由 对应 机器 语 言 码 和/ 或常量 数 据的十六 进 制 编码数 字 组 成。Intel HEX 文件通常用于 传输将 被存于ROM 或者EPROM 中的程序和 数 据。大多 数 EPROM 编 程器或模 拟器使用Intel HEX 文件。
Hex文件是可以烧写到单片机中,被单片机执行的一种文件格式,生成Hex文件的方式由很多种,可以通过不同的编译器将C程序或者汇编程序编译生成hex。
一般Hex文件通过记事本就可以打开。可以发现一般Hex文件的记录格式如下:

Intel HEX 由任意数量的十六 进 制 记录组 成。每 个记录 包含5 个 域, 它们按以下格式排列:
每一组字母 对应 一 个 不同的域,每一 个 字母 对应 一 个 十六 进 制 编码 的 数 字。每一 个 域由至少 两个 十六 进制 编码数 字 组 成, 它们构 成一 个 字 节 ,就像以下描述的那 样:
:(冒号)每个Intel HEX 记录 都由冒 号开头 ; LL 是 数 据 长 度域, 它 代表 记录当 中 数 据字 节 (dd) 的 数量 ; aaaa 是地址域, 它代表 记录当 中 数据的起始地址; TT是代表HEX 记录类 型的域 , 它 可能是以下 数 据 当 中的一 个: 00 – 数 据 记录(Data Record) 01 – 文件结 束 记录(End of FileRecord) 02 – 扩展段地址 记录(ExtendedSegment Address Record)
03 – 开始段地址 记录(Start Segment Address Record) 04 – 扩展 线 性地址 记录(Extended Linear Address Record)
05 – 开始线性地址 记录(Extended Segment Address Record) dd 是数 据域 , 它 代表一 个 字 节 的 数 据. 一 个记录 可以有 许 多 数 据字 节 . 记录当 中 数 据字 节 的 数 量必 须 和数 据 长 度域(ll) 中指定的 数字相符. cc 是校验 和域 , 它 表示 这个记录 的校 验 和. 校 验 和的 计 算是通 过将记录当 中所有十六 进 制 编码数 字 对 的 值相加, 以256 为 模 进 行以下 补 足.
表示为:“:[1字节长度][2字节地址][1字节记录类型][n字节数据段][1字节校验和] ”
-
SWD离线下载研究
声明
本文的标签是编整,大部分的研究内容都是我从网上收集而来,加上我的理解和整理而成,在引用他人的研究内容时,我会注明出处,如有侵权,请联系作者。
本文的研究内容全部开源,可以用于学习,研究,商用,商用时请注明出处。
课题背景
单片机通常有2种下载方式,IAP(in application programming,在应用编程)和ISP(in system programming,在系统编程)。SWD就是典型的IAP编程,SWD还支持在线调试等功能,是一个被广泛使用的下载方式,只需要3线就能实现,即:CLK,IO,GND。现有的常用下载方式都是用PC端通过Jlink/STLink给目标板下载程序,虽然下载调试都比较方便,但是每次都需要连接电脑,在部分场合不是很方便,所以提出了SWD离线下载的研究。
研究意义
SWD离线下载器可以方便工厂批量下载,可以作为技术支持人员的手持下载设备,也可以作为研发人员的下载器,如果再添加无线模块便可以实现无线下载。
一个基于STM32的乞丐原始版SWD离线下载器MDK工程
参考链接:贴一个基于STM32的乞丐原始版SWD离线下载器MDK工程
一只想做一个基于STM32的SWD离线下载器,奈何网上没有一个基于STM32的开源的(主要原因是自己菜)。
坛子里面有许多人做出来的,我曾经发私信问过好几个坛友,希望能够咨询一下,不过没有一个人回复我…尴尬……..
看过基于STM32F103的daplink(就是那个支持拖拽下载的)的源代码,也看过cmsis daplink,程序太复杂了,初学者很难剥离出需要的代码来修改为离线下载器。自己之前也大致研究过这个,也只能是做到读取DP,AP,读取寄存器的程序,今天逛github,发现了一个驱动代码,于是我结合以前我写的代码,也移植了 一些别人的代码,勉强调通了SWD程序下载。 程序是基于STM32c8t6小板做的,还没有做外界FLASH或EEPROM来存程序,只是将一个简单的程序转换为数组,存入单片机的中的。这个其实算不上离线下载器,但是改动一下,作为一个乞丐版的离线下载器还是可以的。 只对STM32F103RCT6进行了测试,目标程序运行正常。
最后贴上MDK工程 同时希望有兴趣的坛友可以继续完善一下,如果您改进了这个程序,恰巧您高兴,可以贴出源代码到这个帖子,或许能够做成第一个开源的离线下载器。 如果没人后续改进,我自己也会慢慢抽时间改进。。这个过程可能很长。。
网盘链接:https://pan.baidu.com/s/1yZ3mPvbIUZMwV83TYl05kw 密码:3cqx
分享离线SWD编程器代码
参考链接:分享离线SWD编程器代码
SWD离线编程器,其实很简单,, 因为关键代码国外的大侠都已经给实现了,,我们只需要简单拼接一下就OK啦
下面我就说下怎样通过拼接代码实现离线编程器:
1、首先,既然是SWD编程器,那首先当然是要实现SWD时序协议了 由于单片机都没有SWD外设,所以只能用GPIO模拟实现SWD时序,,这部分功能已经由ARM公司的CMSIS-DAP代码实现
2、然后就是基于CMSIS-DAP,实现通过DAP读写目标芯片的内存、内核寄存器,,这部分功能已经由DAPLink里面的swd_host.c文件实现
同时,swd_host.c还实现了另一个对实现编程器至关重要的函数:
uint8_t swd_flash_syscall_exec(const program_syscall_t *sysCallParam, uint32_t entry, uint32_t arg1, uint32_t arg2, uint32_t arg3, uint32_t arg4)它的作用是通过DAP在目标芯片上执行
那么,我们只要把编程算法(一段在目标芯片上执行的代码,里面有Flash_Erase、Flash_Write两个函数)通过SWD写入目标芯片的SRAM,然后再通过SWD调用目标芯片SRAM里面的Flash_Erase、Flash_Write两个函数,不就能实现通过SWD给目标芯片编程了吗??
所以,程序的主体结构就是:
其中target_flash_init()的主要作用就是把芯片的编程算法下载到目标芯片的SRAM中去.
好了,SWD编程器已经实现.
不过还有一个问题:要下载到目标芯片SRAM中去的编程算法从哪里来??
我们知道,Keil针对每一颗芯片都有一个Flash编程算法,这个算法存在一个后缀为.FLM的文件里面,,要是我们能把.FLM文件里面的算法内容抽取出来给我们用,,那不就完美了吗
3、其实这个功能也已经有国外大神给实现了,GitHub上的FlashAlgo项目里面有个flash_algo.py文件,它就是用来实现这个功能的
工程示例代码:
另外,这个工程我也已经上传到github上了,,希望坛友能顺便去给加个星,,谢谢啦. https://github.com/XIVN1987/DAPProg
Keil_v5\ARM\Flash_Template目录下有个烧录算法模板,,其中部分函数如下:
对比SWD_flash.c的代码发现一些问题: 1、Keil算法中的函数都是正确返回0、错误返回1,而SWD_flash.c认为函数返回0表示出错 2、Keil算法中Init函数的第三个参数说明,Init函数应该是在Erase、Program、Verify之前各分别执行一次,,而SWD_flash.c的实现只在最开始(也就是Erase之前)调用一次Init
所以,很可能SWD_flash.c不是针对Keil的编程算法写的,,DAPLink项目可能实现了自己的编程算法接口,,而我上面那个STM32的Demo之所以能执行成功,可能是因为: 1、所有函数都没检查返回值, 2、可能在STM32的编程算法中Init函数对Erase、Program、Verify这三个操作执行的内容是一样的,,所以执行一遍Init就行了
不过用在另一些芯片上可能就不行了
所以,我对SWD_flash.c做了一些修正,,不过由于没有板子,暂时没法测试,,感兴趣的坛友可用试一下。
另外如果想实现在线编程器的话,其实GitHub上也有现成的代码可用参考:https://github.com/mbedmicro/pyOCD
在这个项目下有个叫flash.py的文件,其中部分函数如下:
是不是看起来和SWD_flash.c中的函数非常像啊 ,,有了这个文件,实现在线编程器就So Easy了!!
不过也有两个小问题: 1、这个项目是基于CMSIS-DAP(DAPLink)的,如果想用JLink做在线下载的话,需要把底层部分换成jlink.py 2、这是个命令行的项目,想要做个带图形界面的在线下载器的话,需要自己添加GUI功能
继续填坑
下面两段内容分别来自flash_algo.py和c_blob.tmpl
整个编程烧写过程占用了目标芯片4K SRAM,其中SRAM起始地址为0x20000000,栈顶指向4K SRAM的末尾,,编程算法占用4K SRAM的前1K,,待烧写数据占用4K SRAM的中间2K,,静态变量和栈共用4K SRAM的最后1K
这种设计对绝大多数Cortex-M芯片是没有问题的,,不过有几种情况可能需要调整红线框住的部分: 1、SRAM的起始地址不是0x20000000,这种调整最简单,把entry的值调整成正确值就可用了 2、单片机的SRAM小于4K,这种就比较麻烦,得根据实际情况重新规划SRAM的分配,,然后红线框住的部分可能都要改动 3、编程算法内容大于1K,,有些使用片外SPI Flash的芯片它的编程算法会非常大,1K SRAM装不下,,这种把后面几个部分的地址都往后延就行了
所以,对于有些比较特殊的芯片,,需要先修改一下flash_algo.py和c_blob.tmpl,然后再生成算法文件对应的.c文件,,不过还好,生成是一次行的,,
随便一个STM32F103C8的demo板就行,,模拟SWD用的B13、B14两个引脚
参考阅读
拓展阅读
- bin文件如何转换成16进制数组:这个帖子里提到了无线IAP更新程序的问题,有点意思。
-
STMCU程序ISP下载方式
本文分为2部分,第一部分是简单的讲述利用flyMcu上位机和ISP的方式下载程序。第二部分的比较有含金量,主要讲述ISP下载的具体过程,该部分可是自己编写类flyMCU的上位机。
本文测试的目标板为stm32103RcT6。
利用flyMcu下载程序
ISP与IAP
Iap,全名为in applacation programming,即在应用编程,与之相对应的叫做isp,in system programming,在系统编程,两者的不同是isp需要依靠烧写器在单片机复位离线的情况下编程,需要人工的干预,而iap则是用户自己的程序在运行过程中对User Flash 的部分区域进行烧写,目的是为了在产品发布后可以方便地通过预留的通信口对产品中的固件程序进行更新升级。在工程应用中经常会出现我们的产品被安装在某个特定的机械结构中,更新程序的时候拆机很不方便,使用iap技术能很好地降低工作量.
ISP下载前准备
- 编译好的hex文件;
- 电脑以及FlyMcu上位机;
- USB-TTL
ISP下载方式
- Boot0 接到 3.3V 上,Boot1 接到 GND,对板子重新上电,STM32 单片机重启的时候,会进入到 ISP 模式;
- USB-TTL 对接目标板的uart1;
- 打开FlyMcu上位机软件,如下图操作;
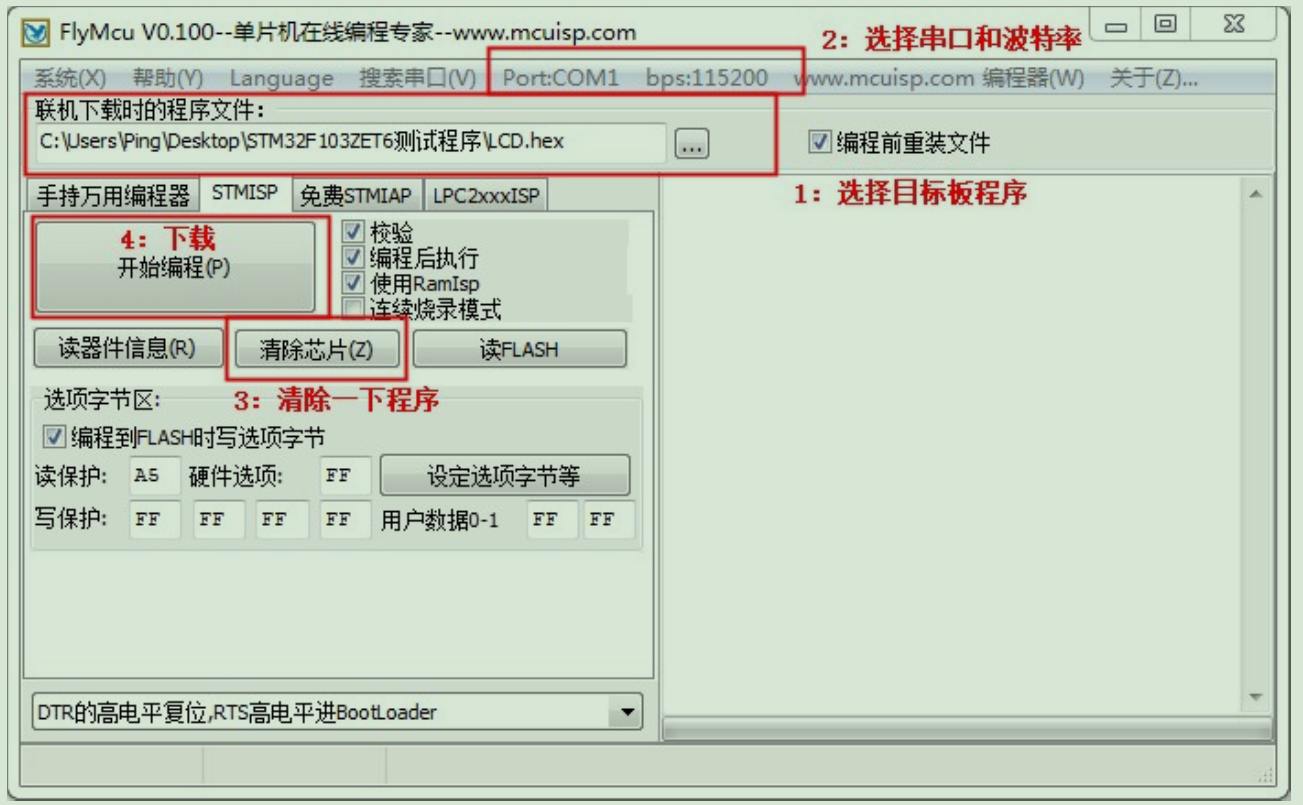
- Boot0和boot1都接到GND,目标板重新上电,或者Rst,即可正常运行程序。
注意事项
- ISP下载需要在单片机离线情况下才能下载,所以需要Rst操作;
- 正常运行时,需要重新设置boot0,boot1;
- IPS下载实际上使用的串口下载,测试时使用的是uart1,理论上uart1在程序中可以正常使用的,因为下载时会将单片机离线;
- 由于ISP下载是串口下载,所以对PC主机要求低,不需要安装Jtag等。
参考阅读
ISP下载过程
参考阅读
-
技术方案目录
这是什么?
技术方案目录是我的产品线的总目录,该目录详细汇总了在我的产品线中会用到的技术方案。同时在该目录的细目中包好了技术方案实现的地址链接。该目录有主要有2个作用,一是作为编写、整理技术方案的总提纲,后面的技术方案总结整理工作都以此目录为准;二是作为后期产品研制时的查找实用工具。因此该目录是一个系统的,全面的,可靠的,方便查找的技术方案目录。
凡是录入该目录的,都是切实可行的技术方案,而不是未经验证的理论,也不是简单的知识点,单纯的知识点不会录入该目录,而会在其他文章中收录。界定知识点和技术方案的简单办法就是该方案是不是可以开发为一个系统或产品。所以该目录的细目并不会很多。
随着时间的推移,需求的变更,该目录会越来越丰富,越系统,越全面。
所有的技术方案都有2个状态变量:研制状态和存档状态。研制状态的值分别是:在研中,原理样机,产品化;存档状态的值分别是:收集中,已存档。
关于存档
和目录保持一致的,在[技术方案归档]中都有对应的技术方案资料,所以[技术方案归档]作为所有目录的实际存储地址。关于[技术方案归档]的建立,暂时没有一个完善的解决办法,因为如果把所有的技术文档都放在[技术方案归档]下,会造成一定程度的存储冗余,尤其是大文件,因为一项技术通常会包含很多资料。一般而言,我会把所有尚未完全整理的资料存放在百度网盘和移动硬盘中做双重备份。也就说着两个地方是原始资料库,但是没有整理的很好,所以不能算是归档。
另一种方法就是在[技术方案归档]中仅仅存放实际技术方案的地址链接,但是这样就失去的建立[技术方案存档]的意义。
于是这里制定一下[技术方案存档]的规范:
- 技术方案存档必须包含关于该技术的文档说明,而不仅仅是一堆原始开发资料;
- 存档必须条例清晰,必要时需要添加ReadMe文件,用以说明存档资料的使用;
- 必须包含原始开发资料,如源代码,电路图等;
- 如果原始资料超过100M,同时在其他地方有双重备份,可以不用在冗余备份,只需要说明实际存放地址即可,但是必要的技术方案文档还是要的。也就说,只要小于100M,则和技术方案相关的资料都应该按要求存档。
- 一旦存档,理论上不会修改,因为方案必须是切实可行的,当然如果实在需要完善和改进可以修改,但是必须添加修改日志和文档说明。
同样的,[技术方案存档]也会在网盘和移动硬盘中存档,其实也可以存放在github上,但是由于github的服务器在美国,而且它也是完全开放的,所以还是放在自己手里安全点。
-
我的产品线-概述
关于我们
我们是一个专业的技术方案和技术服务提供商。
对于产品形式,我们更倾向于为客户提供产品开发方案和服务,而不是单一的产品,因为客户的需求千千万,我们满足不了所有的客户,但是如果我提供的是模块化的技术方案和服务,就可以满足几乎所有客户。当然客户想要具体的产品也是可以的。这样一来,我可以更加专注技术方案的实现和改进,而不用关注产品生产,产品外形和产品应用市场等。
未来的市场一定是垂直细分的,所以我们坚持做技术方案和服务,而不做产品,我们坚信因为细分,所以专业。我们的服务是细致入微的,绝大部分技术方案都是开源的,我们不担心被抄袭,因为我们一直被模仿,从未被超越。
产品线
我们的产品线包含而不限于嵌入式核心模块、终端显控器、电机运动控制和智能算法等技术方案和服务。我们的产品都支持定制,而且推荐定制,但是不代表我们收费很贵。
下面是我们的产品路线图。
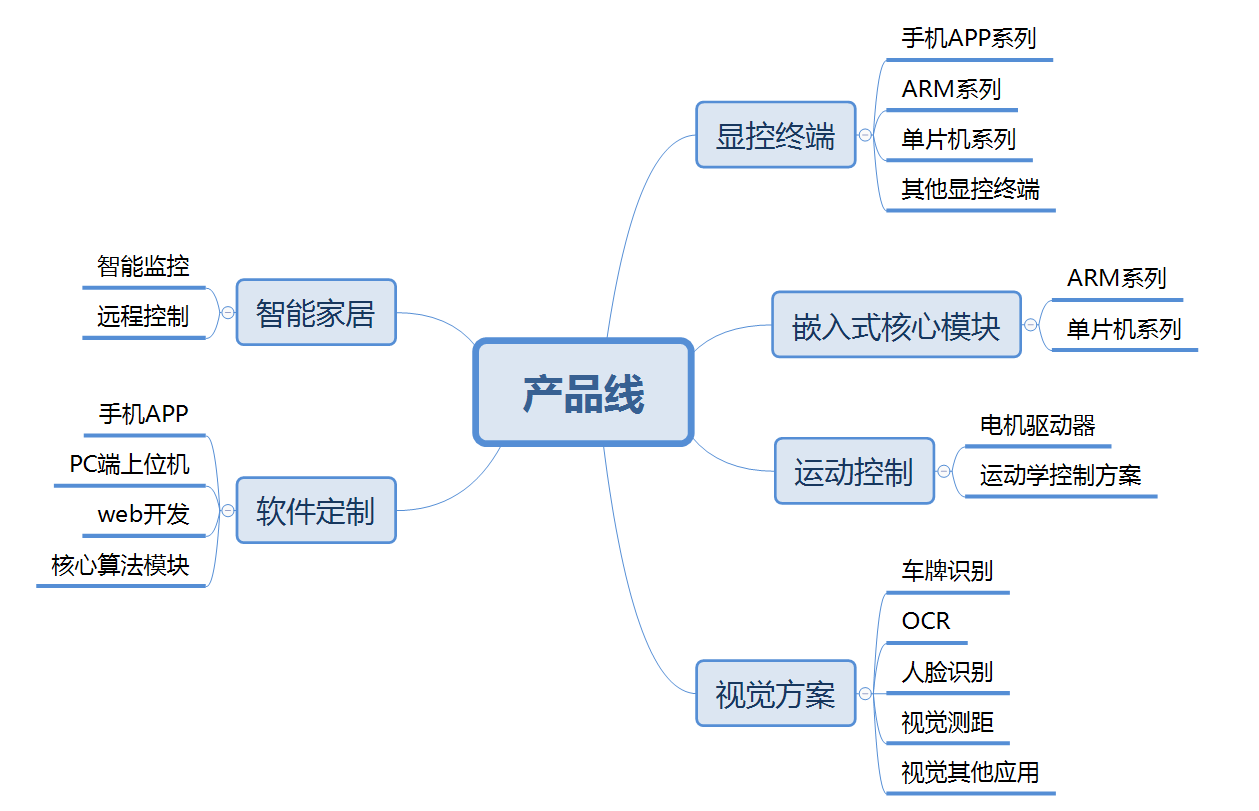
- 显控终端主要包含手持式控制器,远距离无线,近距离无线,无线,低功耗等;
- 嵌入式核心模块主要是机器人或专用设备的主控模块,可以裁剪和定制模块的功能;
- 运动控制模块主要包括电气驱动器和运动学算法控制;
- 视觉方案是指视觉识别算法应用模块,如车牌识别、人脸识别等;
- 软件定制是指我们可以根据客户的需求定制手机APP、PC端的上位机软件以及核心算法模块;
- 智能家居模块主要是一些远程监控的方案;
在本站的其他文章中会分别详细说明各个产品的技术方案和技术指标。
-
Android开发-汇总